Last Friday just happened to be black Friday with retailers offering massive bargains. Traditionally the concept was accepted in EU in 2010, and records suggest that Amazon UK had the busiest day with about 64 items sold per second and sales of about 5.5million goods. Most of the retailers traditionally have been building sites with a view to offer uptime ranging 95%-99.7%, and someone like amazon aiming for 99.9% availability.
Now when we talk about availability, we talk about resilience and one of the finest quote that I read is “Resilience is all about being able to overcome the unexpected. Sustainability is about survival. The goal of resilience is to thrive. – Jamais Cascio”.
While big names in UK retail like John Lewis, Tesco and Argos struggled with traffic, and Currys provided some sense to the traffic by introducing a virtual queue. Realistically speaking, if we see it all boils down to how well is the infrastructure defined for these sites. As a no brainer, all of decent retailers have some level of SOA based approach to the services they use. When I talk about services, nothing better occurs to me than the netflix model “Hysterix”.
In my view one should consider using Hystrix as a framework with guided principles to implement on the solution. The image below which is reproduced from netflix, tries to explain in simple terms.
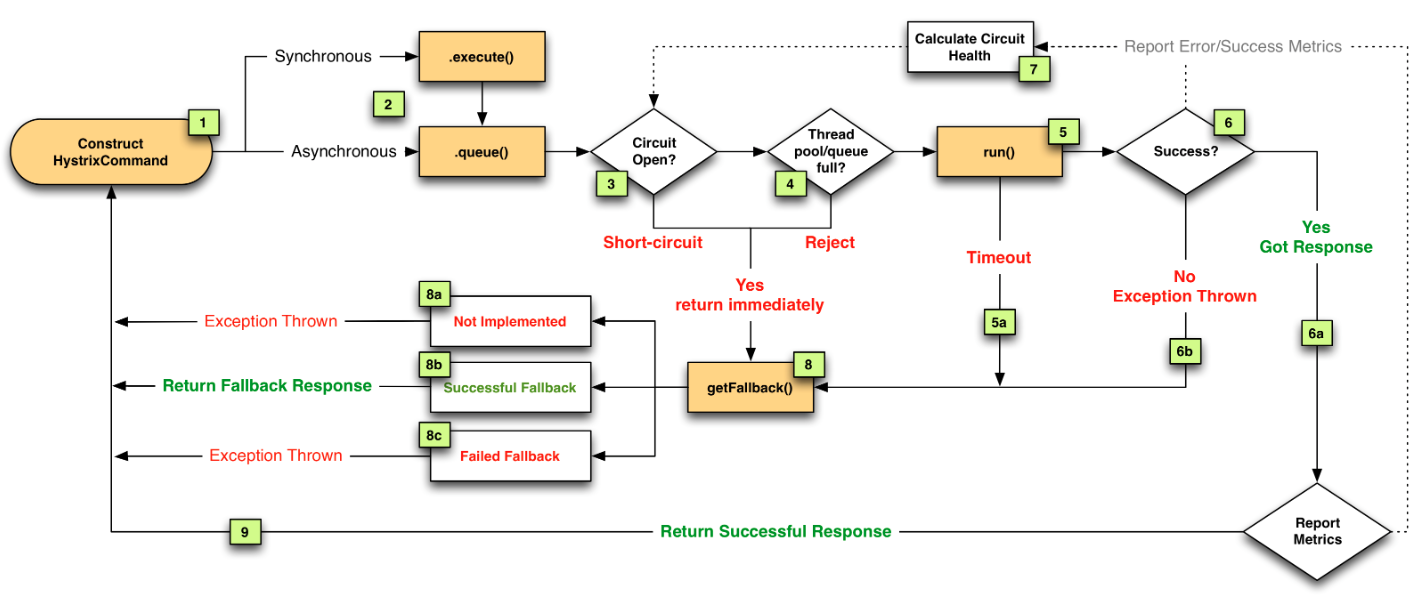
Hystrix
The design principle is fairly simple:
- You want maximum uptime.
- You want system to automatically correct itself after failure.
- You want a view to understand how system is performing at any point in time and over any period.
Depending on your existing system, you can implement Hystrix model by either using the codebase (open source) provided by netflix, which I think has its own drawback, since then you end up tying lot of dependencies on numerous jars of netflix. (hystrix code depends on some jar and then another and other). Flipcart (an indian competitor of Amazon and ahead in indian market), has also used a version of Hystrix, by tweaking the api. You can search for Flipcart’s api, which is available on github.
Or you can treat hystrix a purely a principle and introduce bunch of things which lets you fulfil the objective.
Lets take two cases, one of address service, which is very common in any implementation and is not critical in customer journey, other one can be bank card service, which is absolutely a must.
So first thing you can do is build a generic framework of error handling and service call management, where your custom code calls this facade, which delegates call to third party provider (or your internally hosted service, which calls 3rd party e.g. QAS) This facade keeps track of how the service has been performing, and manages a thread pool for requests, and knows what is the average thread response time, and in case it notices any deviations, it know there is an issue with service and can “Fail Fast” to trigger your alternative option (in this case a manual address entry interface). Next thing you can do is using the same guidelines of hystrix, configure service retries and time-outs.
If you take a more critical service like bank card, you use same steps as outlined above, however, have additional cushioning with set of business processes in place e.g. offering customer to leave the details so that customer service can call and complete the order, or offering them alternative payment methods e.g. Paypal, which would not be via the same bank card service provider, hence at least you will have mechanism to take payments online if one option faults.
If I look at what Currys did on the sale was clever and very basic. It expected a surge in traffic and also knew its infrastructure capability, hence introduced a virtual queue, and wait time was purely governed by the traffic. This is probably the cheapest solution one can build. It does not allows all the users on the site at same time, however it lets each user to buy the items and maintains the credibility of not being down.
Till now I have talked about services and bringing resilience to systems via them, however a site compromises of core technologies apart from services.
Tesco, John Lewis are build on Oracle ATG and Argos on WCS. Both these products are market biggies, however being in the world of Oracle ATG, I will advocate one need to think of infrastructures differently and consider the deployment topology in an untraditional fashion, as much as a banking system will demand. If we talk of ATG specifics, you need to think how can you have Storefront instances which are countless, but start up only on the need. This then should let you think how you package the ear, how do you get server specific configs, so that an ear can be deployed on any ATG standalone server and it still works same as on any other instance. As long as you have a virtual farm of servers, you can create such ears and deploy them as per the need, what it would not offer is flexibility around BCC and all associated activities, however BCC is a back end operational tool, and if you have defined your business processes well enough (i.e. not tying everything too tightly to merchandising server), you have the choice to offer continuity to outside customers/users, though you may have offer a degraded service i.e. product details may be out dated for a few product which is not able to get pushed due to BCC being down, or you may think of not using BCC at all.
There are numerous ways to slice this cake, important is that retailers start thinking of resilience with all seriousness and create an eco-system of products and services that can work seamlessly. Amazon is already there, its an undisputed leader, are you there?
